
The Importance of Timely Post-Discharge Care
Effective post-discharge care is critical for patient recovery and preventing costly readmissions. Research consistently shows that timely and appropriate follow-up significantly reduces readmission rates and improves patient outcomes. For instance, a study showed that a timely follow within 14 days after discharge is associated with a 19.1%-point reduction in readmission rate among high risk Medicaid patients [1]. Despite the evidence, identifying which patients need immediate follow-up remains challenging in practice.
The Limits of ADT-Only Discharge Identification
Traditional approaches to identifying discharges often rely on Admission, Discharge, and Transfer (ADT) data. While ADT feeds signal a patient’s discharge, diagnoses and severity information are often delayed or missing. This makes it challenging for care providers to prioritize and personalize post-acute interventions.
Additionally, ADT feed coverage varies across healthcare facilities and geographic regions, further limiting its reliability as a standalone signal for post-discharge care planning.
Introducing A Predictive Approach to Discharge Prioritization
Rather than relying solely on discharge alerts, Pearl’s solutions have enabled clients to improve discharge follow up rate and reduce readmission rates. For example, at Pearl we observed a 17% reduction in readmissions among clients who consistently engaged with our platform. One of our innovations is the use of advanced machine learning to triage inpatient episodes according to severity and the likelihood of readmission. Our technique supplements the ADT feed data with a machine learning model designed to predict patient diagnoses and severity by using historical claims data to look beyond immediate discharge data. These models infer the likelihood of chronic conditions exacerbation that might be related to their recent hospitalization.
Why Diagnosis Codes Alone Aren’t Enough
Diagnosis and procedure codes are standardized systems for classifying patient conditions and medical services, but they are challenging to directly use in any statistical and machine learning algorithms due to their sheer volume and redundancy.
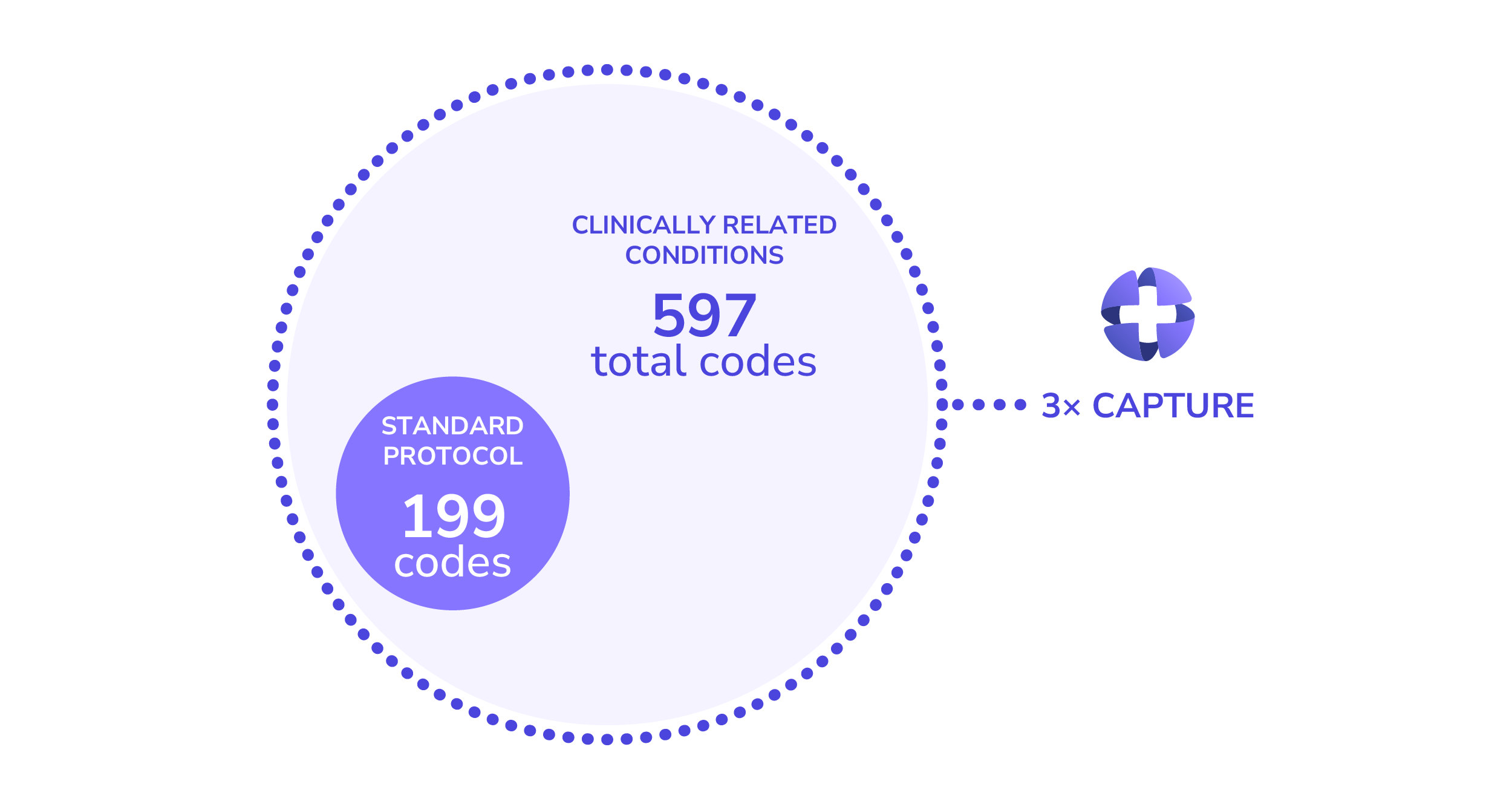
For instance, hundreds of codes describe diabetes and its complications, yet only a small subset indicating acuity typically trigger standard triage algorithms. In practice, providers may bill using a clinically similar code that is not listed in the triage algorithm, leading to missed care opportunities.
Capturing clinical similarity across billed diagnosis codes and high acuity codes is therefore essential to accurately predict potential exacerbation of the condition.
Capturing Clinical Similarity using NLP
To capture meaningful clinical relationships across diagnosis and procedure codes, Pearl uses natural language processing (NLP) to incorporate all of these codes into our predictive models. Specifically, we use Clinical BERT, a Bidirectional Encoder Representations from Transformers (BERT) architecture–a modern technology behind large language models (LLMs)--fine tuned with medical texts, to learn how clinically related conditions behave in practice [2].
This approach represents diagnosis and procedure codes as numerical representations (embeddings) that encode semantic meanings and similarity between conditions. These embeddings preserve clinical relationships and enable more computationally efficient, accurate risk modeling, unlike traditional encoding methods, which yield sparse, high dimensional representations, and treat each code independently.
From Clinical Embeddings to Better Care Decisions
This AI powered approach supplements manually curated clinical rules and improves our ability to identify at-risk patients who need timely and preventive care.
For example, the Centers for Medicaid and Medicare Services (CMS) provides accountable care organizations (ACOs) with lists of diagnoses that qualify discharges for timely follow up to prevent chronic condition exacerbation. While tachycardia is included as related to coronary artery disease (CAD) and congestive heart failure (CHF), bradycardia is not, even though it can occur following a tachycardia episode due to sinus node dysfunction.
If bradycardia alone is coded, a patient may not be flagged as high risk under traditional rules. Pearl’s clinical embeddings group these related arrhythmia symptoms together, allowing care teams to identify at-risk patients who might otherwise be missed.
Visualizing Risk Across Patient Populations

The visualization below summarizes patients' diagnosis histories and highlights clinically similar patients. Diagnosis embeddings are reduced to 3D space and clustered, with each cluster color-coded by risk level. The green cluster represents low-risk patients, yellow medium-risk patients, and red high-risk patients.
Model Interpretation and Validation
Model interpretability analysis shows that predictors based on semantic similarity of diagnosis codes rank among the top five most important features out of 100+ predictors used to predict high risk patients.
Backtesting results have shown that, compared to ADT-only approaches, Pearl’s model incorporating diagnosis and procedure code similarity was four times more successful at identifying the patients who require immediate post-discharge care–without increasing false positives.
What This Means for Post-Discharge Care
At Pearl, we are on a mission to empower care teams to proactively deliver high quality and efficient post-discharge care. By applying AI to overcome data gaps and surface clinically meaningful risk signals earlier, we help organizations improve patient outcomes and reduce unnecessary utilization.

- Jackson C, Shahsahebi M, Wedlake T, DuBard CA. Timeliness of Outpatient Follow-up: An Evidence-Based Approach for Planning After Hospital Discharge. The Annals of Family Medicine. 2015;13(2):115. doi:10.1370/afm.1753
- Emily Alsentzer, John Murphy, William Boag, Wei-Hung Weng, Di Jindi, Tristan Naumann, and Matthew McDermott. 2019. Publicly Available Clinical BERT Embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, pages 72–78.
Pearl Health is powering the future of healthcare
We’re a team of physicians, technologists, and risk-bearing experts with a passion for enabling our partners to deliver better care and reduce health system costs. Want to learn more?

