



Thanks to a successful 2022, Pearl Health began 2023 with a 10x increase in data volume compared with the previous year. This blog post focuses on how we solved for database optimization — one of the critical infrastructure changes needed to support higher data volume — and addressed an often-overlooked aspect of databases that was causing severe performance issues.
Read on to learn how discovering and fixing input/output (I/O) bottlenecks doubled our Amazon Relational Database Service (RDS) throughput, allowing us to improve our data ingestion speed and view refresh times by more than 80% while costing just 67 cents per day. Specifically, we delve into how I/O baseline and burst throughput works for AWS RDS instances and how to interpret and monitor burst credits using the “byte balance” metric from RDS.
Engineering for Growth: The Database Optimization Challenge
Our ingestion pipeline is orchestrated by Apache Airflow1 and hosted in Amazon Web Services (AWS) using their Managed Workflows for Apache Airflow (MWAA) service.2 The pipeline involves the following steps:
- Copy a set of flat files, containing Medicare claims data, from a remote SFTP server to our S3 data lake.
- Format and copy the S3 data into our RDS data warehouse, using Python and Airflow.
- Refresh the materialized views that depend on the tables that were updated.
For this post, we are going to focus on steps two and three.
Before 2023, step two involved downloading files from S3 onto the local disk of an Airflow node, and then using a custom Airflow operator to pipe the file contents into PostgreSQL. To skip the local disk bottleneck, in 2023 we decided to implement a new approach that leveraged the aws_s3 PostgreSQL extension,3 which allows the database to stream data directly from the S3 API.
To validate and test our pipelines, we generated synthetic flat files 10 times the size of what we previously had, resulting in a dataset of around 100 GB. We ran our existing ingestion pipelines (on a test stack) on the synthetic data and validated for scalability, data integrity, and performance.
Our early test results were very promising. When we tried manually running the table_import_from_s3() function, our processing time for a 10 GB file dropped from three hours down to 30 minutes. However, after incorporating the new method into our Airflow directed acyclic graph (DAG), we found that the expected improvement hadn’t carried over. Loading the files from S3 still took over three hours, and materialized view refreshes took over 8 hours.
Digging into this issue, we realized that concurrency was a factor. The Airflow jobs performed well when we ran them one-by-one, but experienced extreme latency when running them in parallel, which posed a challenge for us because we needed to run the jobs in parallel. Our data was partitioned by organization, which meant that one job only ingested a portion of the data. Since each job was estimated to take at least an hour, we needed to trigger all three jobs at the same time for maximum efficiency.
When completing database optimizations, the most common monitored metrics are CPU utilization, disk usage, and free memory, so we started by looking at any potential issues with these. However, utilization was within normal ranges for all of them, and so we moved on to another shared but often overlooked resource for databases: disk I/O.
The Culprit: Disk I/O Throughput
Normally, we would expect disk write latency to be in the 5-10ms range, but when we ran our jobs, write latency was around the glacial speed of 100ms! Looking further, we also determined that other metrics like disk queue size showed anomalies during the period, with I/O requests building up.
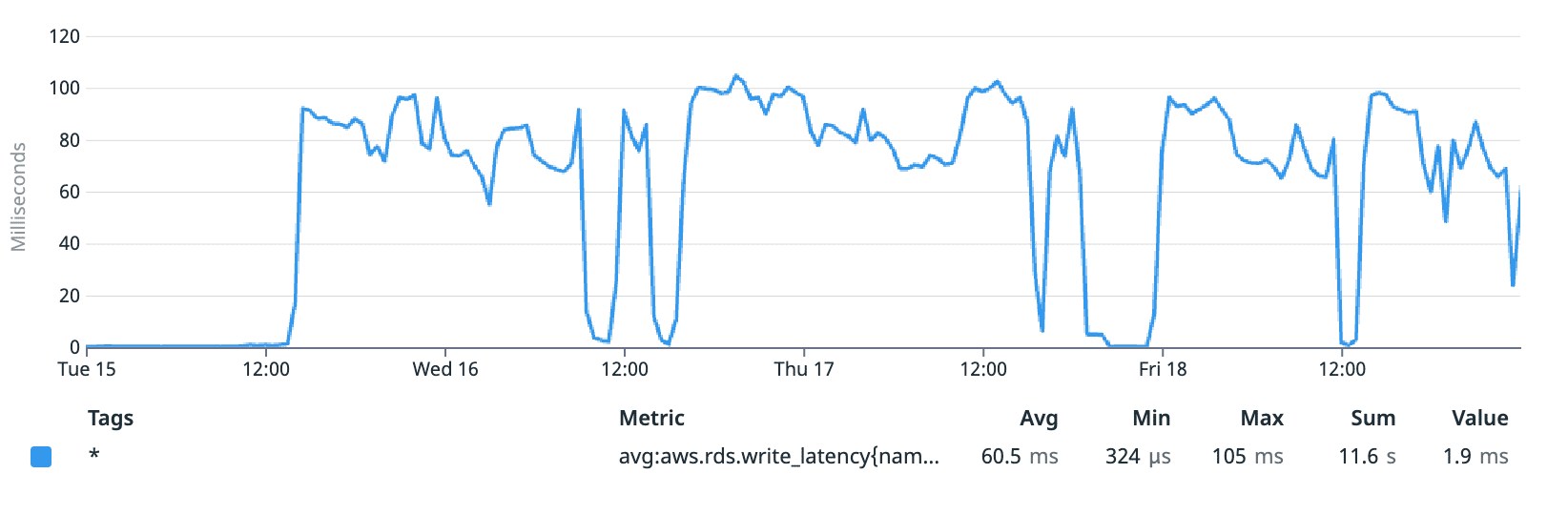
Write latency during our tests (ms)
db.t3.xlarge instance type had a base I/O limit of 86 MB/s for throughput and 4,000 operations/s. Note these are shared across reads and writes. In addition to our base limit, AWS RDS allows 30-minute periods of burst performance in I/O. For the db.t3.xlarge instance type, we were able to burst up to 347.5 MB/s of throughput and 15,700 operations/s.
Looking at our throughput metrics confirmed that we were stuck at that 86 MB/s mark for long periods of time, with short bursts up to about 300 MB/s. We suspected that our I/O limits were the bottleneck slowing down performance. 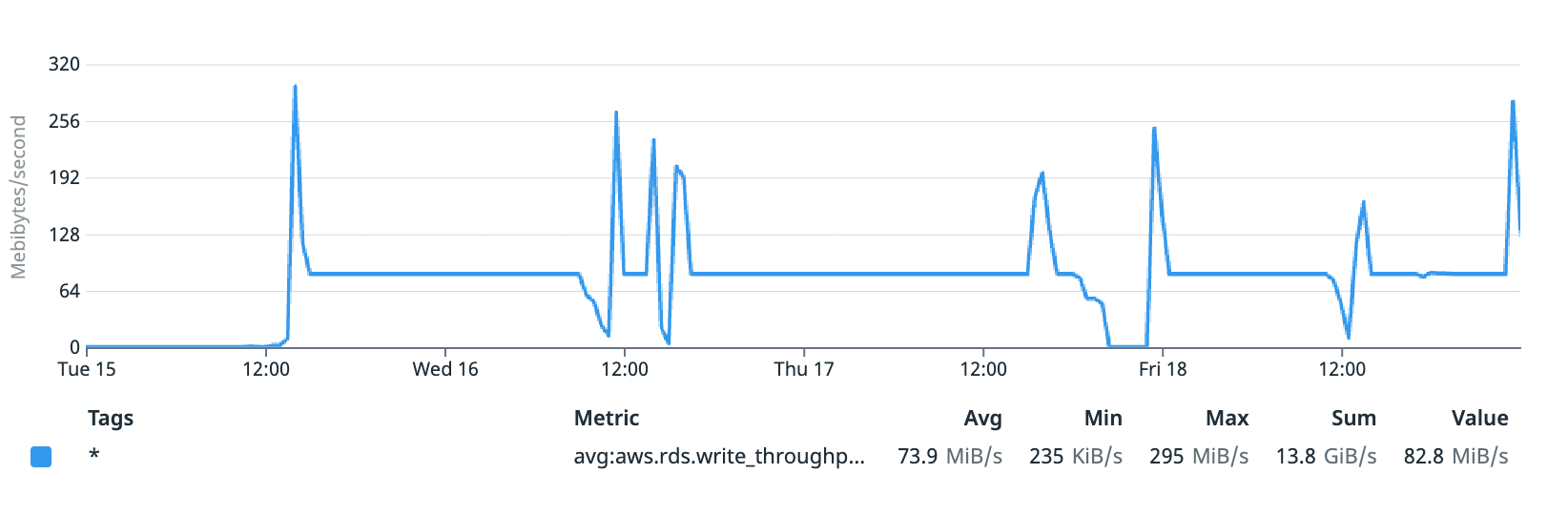
Read + Write throughput during our tests (MB/s)
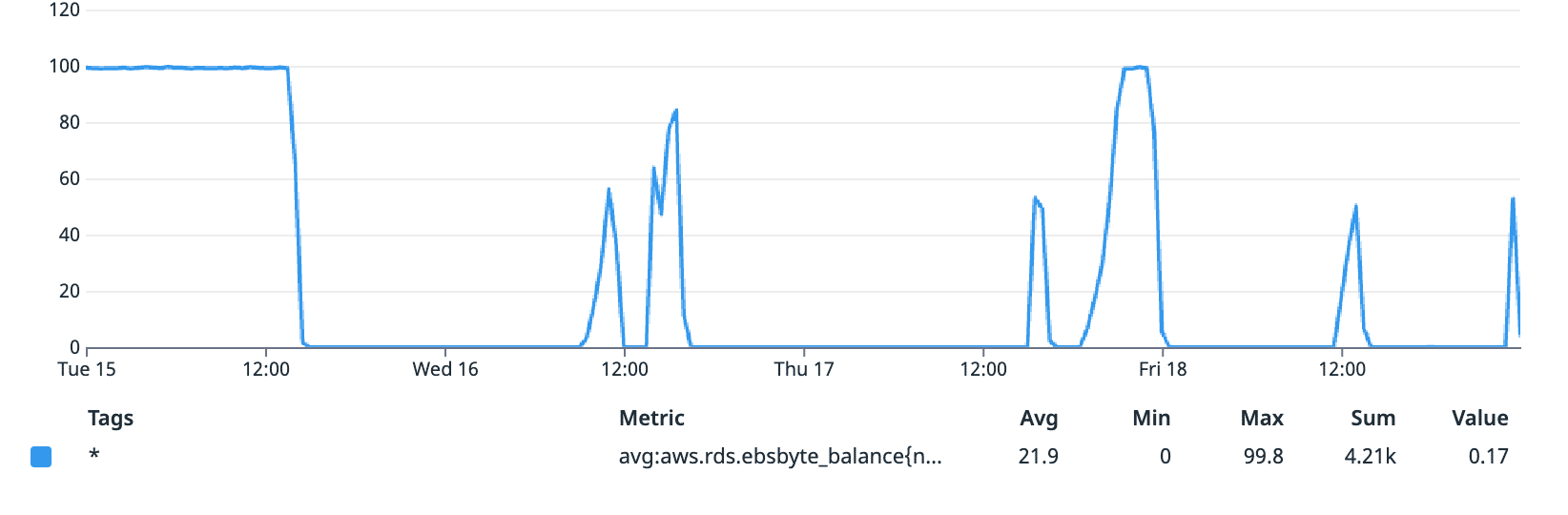
EBS Byte balance during our tests (%)
After confirming the issue with instance type, we looked at EBS volume type, which can also impact I/O performance. We determined that the gp2 EBS storage we were using across our instances was not creating performance issues. While gp2 offers a maximum throughput of 250 MB/s per volume, RDS automatically stripes across four volumes for storage sizes of at least 1 terabyte, which is the storage volume for our RDS instance. Since our throughput went above 500 MB/s during testing, we know that there are most likely 4 EBS volumes in our database with a throughput of 250 MB/s each, providing even more speed than we needed for our desired database setup. This confirmed that gp2 was sufficient, but that if we decided to provision throughput apart from storage capacity in the future, we would need to consider the gp3 volumes.
Improving Baseline and Burst I/O Throughput
At this point, we knew that I/O throughput was the bottleneck slowing down our data ingestion pipelines, and that we needed to find a new instance type with a high enough baseline and burst throughput to support our needs. After weighing the pros and cons, we chose db.m6g.xlarge, which cost us just 67 cents more per day and offered double the baseline I/O throughput of 150 MB/s vs. 86 MB/s, as well as a higher burst capacity of up to 600 MB/s vs. 347.5 MB/s.
Based on this change, we not only saw the 83% performance increase from using the aws_s3 extension to copy files from S3 to PostgreSQL, but also saw an almost 90% improvement in our materialized view refresh times, reducing from 8+ hours to less than 1 hour.
As shown in the graphs below, throughput can now burst up to almost 600 MB/s and write latency maxes out around 50ms.
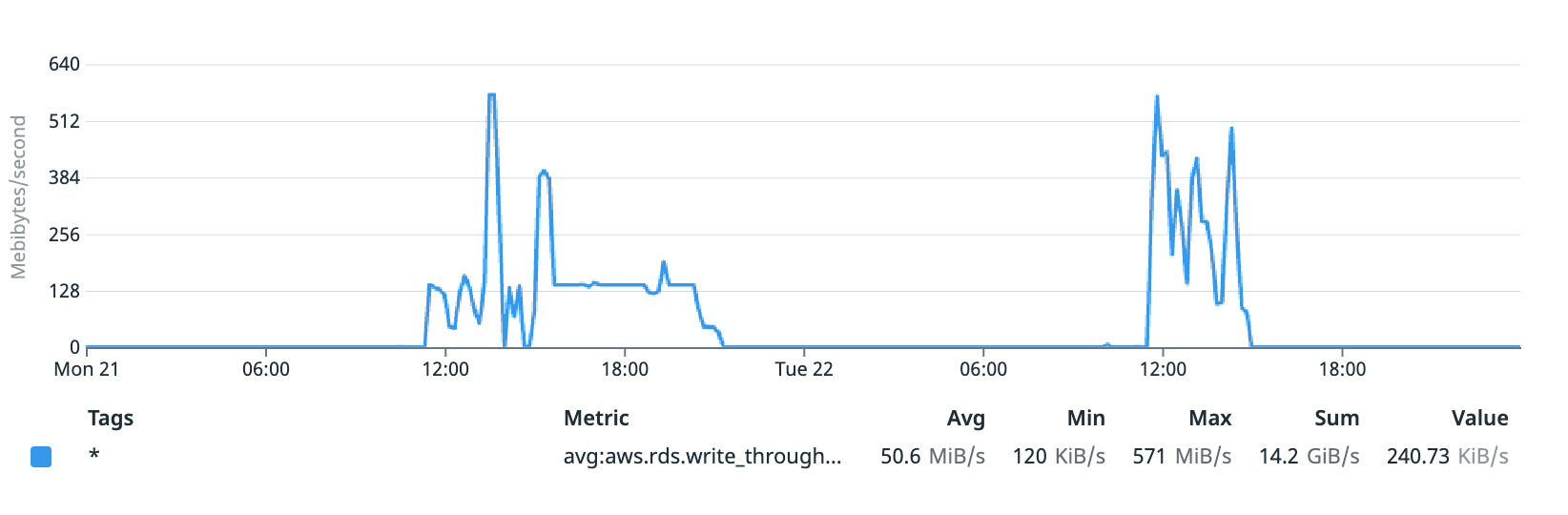
Read + write throughput with the m6g.xlarge instance (MB/s)
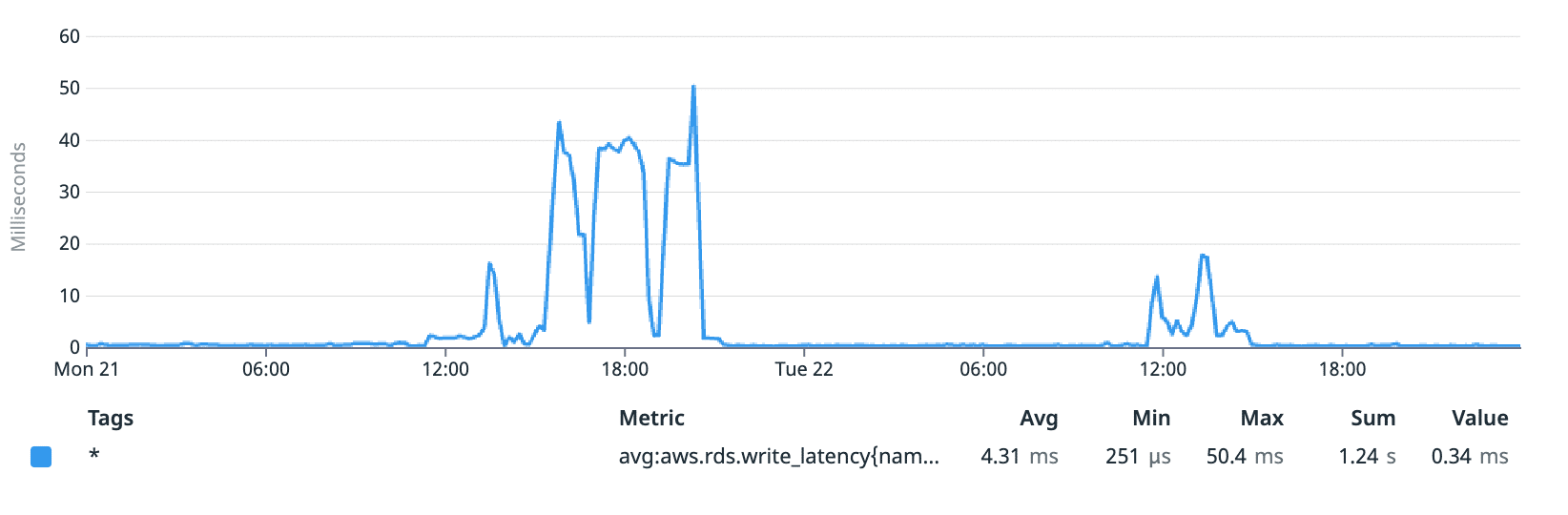
Write latency with the m6g.xlarge instance (ms)
While the EBS byte balance can be depleted for brief periods of time, even the baseline without burst speeds is high enough that the overall process completes in a reasonable amount of time.
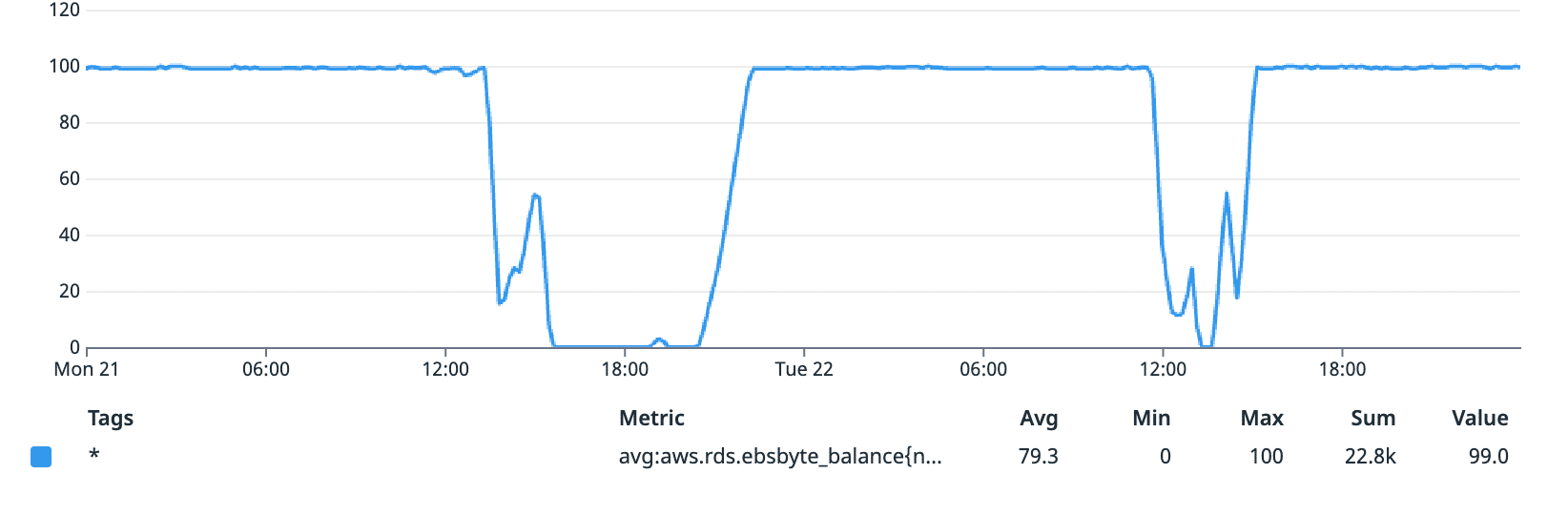
EBS byte balance with the m6g.xlarge instance (%)
As a future-proofing measure, we also added an alert on the EBS byte balance of our database. Whenever the EBS byte balance hits 0 and stays there consistently for an hour, The Pearl Health engineering team is automatically notified using Slack.
Conclusion
While RAM, CPU, and disk usage are important metrics to monitor when debugging database performance issues, I/O limits should also be closely monitored. For AWS RDS, there are different limits for throughput and input/output operations per second (IOPS) for each instance type. In order to avoid any surprises when it comes to performance, one should closely monitor the throughput, burst credits, and IOPS of the database, and upgrade to an appropriate instance type when necessary.
Interested in working on problems like this while helping primary care providers succeed in value-based care? Keep an eye out for opportunities on the Pearl Health Careers Page! Our team of provider-enablement, risk-bearing, and technology experts are thoughtfully building a values-based team to democratize access to healthcare risk, align incentives with patient outcomes to deliver higher-quality care at a lower cost, and to make our healthcare system more sustainable.
Our Technology
- Airflow™ is a platform created by the community to programmatically author, schedule and monitor workflows. For more information, see airflow.apache.org
- Amazon Managed Workflows for Apache Airflow is a managed orchestration service for Apache Airflow that can be used to setup and operate data pipelines in the cloud at scale. For more information, see Amazon’s User Guide, “What is MWAA?”
- Data that’s been stored using Amazon Simple Storage Service can be imported into a table on an RDS for PostgreSQL DB instance. For more information, see Amazon’s User Guide, “Importing data from Amazon S3 into an RDS for PostgreSQL DB instance.”
- An Amazon EBS–optimized instance uses an optimized configuration stack and provides additional, dedicated capacity for Amazon EBS I/O. For more information, see Amazon’s User Guide for Linux Instances, “Amazon EBS-optimzed instances.”
